LENGUAJES DEL SGBD
Todos los SGBD ofrecen lenguajes e interfaces apropiadas para
cada tipo de usuario: administradores,diseñadores, programadores de
aplicaciones y usuarios finales. Los lenguajes van a permitir al administrador
de la BD especificar los datos que componen la BD, su estructura, las
relaciones que existen entre ellos, las reglas de integridad, los controles de
acceso, las características de tipo físico y las vistas externas de los
usuarios. Los lenguajes del SGBD se clasifican en:
- Lenguaje
de definición de datos (LDD o DDL): se utiliza para especificar el esquema
de la BD, las vistas de los usuarios y las estructuras de almacenamiento. Es el
que define el esquema conceptual y el esquema interno. Lo utilizan los diseñadores
y los administradores de la BD.
- Lenguaje
de manipulación de datos (LMD o DML): se utilizan para leer y actualizar los
datos de la BD. Es el utilizado por los usuarios para realizar consultas,
inserciones, eliminaciones y modificaciones. Los hay procedurales, en los que
el usuario será normalmente un programador y especifica las operaciones de
acceso a los datos llamando a los procedimientos necesarios. Estos lenguajes
acceden a un registro y lo procesan. Las sentencias de un LMD procedural están
embebidas en un lenguaje de alto nivel llamado anfitrión. Las BD jerárquicas y
en red utilizan estos LMD procedurales.
No procedurales son los
lenguajes declarativos. En muchos SGBD se pueden introducir interactivamente
instrucciones del LMD desde un terminal, también pueden ir embebidas en un
lenguaje de programación de alto nivel. Estos lenguajes permiten especificar
los datos a obtener en una consulta, o los datos a modificar, mediante
sentencias sencillas. Las BD relacionales utilizan lenguajes no procedurales
como SQL (Structured Quero Language) o QBE (Query By Example).
- La mayoría de los SGBD
comerciales incluyen lenguajes de cuarta generación (4GL) que permiten al usuario desarrollar
aplicaciones de forma fácil y rápida, también se les llama herramientas de
desarrollo. Ejemplos de esto son las herramientas del SGBD ORACLE: SQL Forms
para la generación de formularios de pantalla y para interactuar con los datos;
SQL Reports para generar informes de los datos contenidos en la BD; PL/SQL
lenguaje para crear procedimientos que interractuen con los datos de la BD.
Todos los SGBD ofrecen lenguajes e interfaces apropiadas para
cada tipo de usuario: administradores,diseñadores, programadores de
aplicaciones y usuarios finales. Los lenguajes van a permitir al administrador
de la BD especificar los datos que componen la BD, su estructura, las
relaciones que existen entre ellos, las reglas de integridad, los controles de
acceso, las características de tipo físico y las vistas externas de los
usuarios. Los lenguajes del SGBD se clasifican en:
- Lenguaje
de definición de datos (LDD o DDL): se utiliza para especificar el esquema
de la BD, las vistas de los usuarios y las estructuras de almacenamiento. Es el
que define el esquema conceptual y el esquema interno. Lo utilizan los diseñadores
y los administradores de la BD.
- Lenguaje
de manipulación de datos (LMD o DML): se utilizan para leer y actualizar los
datos de la BD. Es el utilizado por los usuarios para realizar consultas,
inserciones, eliminaciones y modificaciones. Los hay procedurales, en los que
el usuario será normalmente un programador y especifica las operaciones de
acceso a los datos llamando a los procedimientos necesarios. Estos lenguajes
acceden a un registro y lo procesan. Las sentencias de un LMD procedural están
embebidas en un lenguaje de alto nivel llamado anfitrión. Las BD jerárquicas y
en red utilizan estos LMD procedurales.
No procedurales son los
lenguajes declarativos. En muchos SGBD se pueden introducir interactivamente
instrucciones del LMD desde un terminal, también pueden ir embebidas en un
lenguaje de programación de alto nivel. Estos lenguajes permiten especificar
los datos a obtener en una consulta, o los datos a modificar, mediante
sentencias sencillas. Las BD relacionales utilizan lenguajes no procedurales
como SQL (Structured Quero Language) o QBE (Query By Example).
- La mayoría de los SGBD
comerciales incluyen lenguajes de cuarta generación (4GL) que permiten al usuario desarrollar
aplicaciones de forma fácil y rápida, también se les llama herramientas de
desarrollo. Ejemplos de esto son las herramientas del SGBD ORACLE: SQL Forms
para la generación de formularios de pantalla y para interactuar con los datos;
SQL Reports para generar informes de los datos contenidos en la BD; PL/SQL
lenguaje para crear procedimientos que interractuen con los datos de la BD.


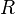 está en 3 Forma Normal
está en 3 Forma Normal  , se cumple al menos una de las siguientes condiciones:
, se cumple al menos una de las siguientes condiciones: es superllave o clave.
es superllave o clave. es atributo primo de
es atributo primo de 
 es completamente funcional si al eliminar los atributos A de X significa que la dependencia no es mantenida, esto es que
es completamente funcional si al eliminar los atributos A de X significa que la dependencia no es mantenida, esto es que  . Una dependencia funcional
. Una dependencia funcional  que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es
que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es  .
. HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI
HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI 












{kind=link}